 |
 |
3kworld.com Sponsor Message |
 |
|
|

July 2001
Boosting your e3000 productivity
IMAGE Internals
By Bob Green
IMAGE is the database of the HP e3000 system, and some knowledge of how it works is useful for anyone doing IT work on the system. “Master Datasets” are one of the storage types of IMAGE and their job is to store records when there is one record expected per unique key field (also the search field). For example, one customer record per customer number.
IMAGE uses a mathematical formula called a hashing algorithm to transfer the key value into a record number within the master dataset. This “hash location” is the first place where IMAGE tries to store the record.
Figure 1 below shows a hashing algorithm with a collision - same block.
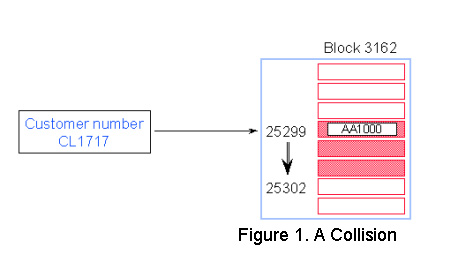
• Customer number CL1717 hashes to the same record number as AA1000 location.
• IMAGE/SQL tries to find an empty location in the same block. If it finds one, no additional IO is required.
• CL1717 becomes a secondary entry. Primary and secondary entries are linked using pointers that form a chain.
Although hashing algorithms are designed to give unique results, sometimes IMAGE calculates the same record number for two different search item values. In this case a new entry may want to occupy the same space as an existing Primary entry. This is known as a collision, and the new entry is called a Secondary.
Most master datasets have secondaries. If you have a lot of secondaries, or if they are located in different blocks, you should be concerned about generating more IOs than needed.
In Figure 1, customer number CL1717 collides with AA1000, and CL1717 becomes a secondary. IMAGE/SQL then tries to find the closest free record location. In this case, the next empty record number is 25302, which is in the same block. No additional I/O is needed.
IMAGE/SQL uses pointers to link the primary entry with its secondary. Record 25299 for AA1000 has a pointer to record number 25302 and vice versa. This is known as a synonym chain.
Several programs can help identify inefficiencies in IMAGE databases. One, a program written by Robelle and distributed to Robelle and Adager customers, is called HowMessy. There is a very similar contributed program, Dbloadng, upon which HowMessy was patterned. Another option is the report feature of DBGeneral.
All these programs produce a report that shows the database’s internal efficiency. Databases are inefficient by nature. Unless you never add new entries or delete existing entries (e.g., use your database for archival purposes), your database becomes more inefficient over time.
In the rest of this column we will examine the HowMessy/Dbloadng reports for two example master datasets.
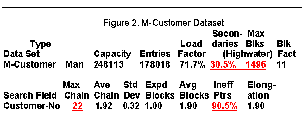
In a Manual Master Dataset (see Figure 2, above):
• The number of secondaries is not unusually high.
• However, there may be problems:
• Records are clustering (high Max Blks).
• Long synonym chain.
• High percentage of Inefficient Pointers.
The values in Figure 2 are understood as follows:
Secondaries: Percentage of entries that are secondaries
Max Blks: Maximum number of contiguous blocks IMAGE/SQL has to read before finding a free location for a secondary. This is the worst-case scenario, not the actual number.
Blk Fact: Blocking Factor column indicates the number of records in each block (not an MPE/iX page).
Search Field: Key item name.
Max Chain: Maximum number of entries in the longest synonym chain.
Ave Chain: Average number of entries in the synonym chain.
Std Dev: Standard deviation shows the deviation from the average that is required to encompass 90% of the cases. If the deviation is small, then most chains are close to the average.
Expd Blocks: Number of blocks we expect to read in the best-case scenario (usually 1.00 for master datasets) to get a whole synonym chain.
Avg Blocks: Number of blocks needed to hold the average chain.
Ineff Ptrs: Percentage of secondary entries that span a block boundary.
Elongation: Average number of blocks divided by the expected number of blocks.
Figure 2 does not show a tidy dataset. The number of secondaries is fairly high (30.5 percent, or around 54,000). The Maximum Chain length is 22. This is unusual for a master dataset. The high Max Blks value (1,496) suggests some clustering. All of this indicates that the hashing is not producing random distribution. If you add a new record whose primary address happens to be the first block of the contiguously-occupied 1,496 blocks, IMAGE/SQL will have to do many extra disk IOs just to find the first free entry for the new record (assuming that MDX has not been enabled on this dataset).
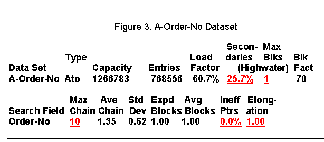
Figure 3 above shows an Automatic Master Dataset.
• This is a very tidy dataset:
• Number of secondaries is acceptable.
• Max Blks, Ineff Ptrs and Elongation are at the minimum values, even if the Maximum Chain length is a bit high
Although the percentage of secondaries is similar to that of the M-Customer dataset of Figure 2 (30.5 percent versus 25.7 percent), the longest synonym chain has 10 records with a 1.35 average. The Inefficient Pointers and Elongation are at their lowest values. Max Blks of 1 means IMAGE/SQL can find a free record location within the same block every time it searches for one.
It means the hashing algorithm is working correctly, dispersing records evenly across the dataset.
There is, of course, much more to learn about IMAGE internals and performance. This short column is to whet your appetite for a two-hour tutorial, “IMAGE Internals and Performance” which I will present at HP World. See you there in Chicago on Tuesday, August 21 at 1 PM.
Copyright The 3000 NewsWire. All
rights reserved.