 |
 |
Nobix Sponsor Message |
 |
|
|

May 2001
Boosting your e3000 productivity
From IMAGE to HTML!
By Ken Robertson
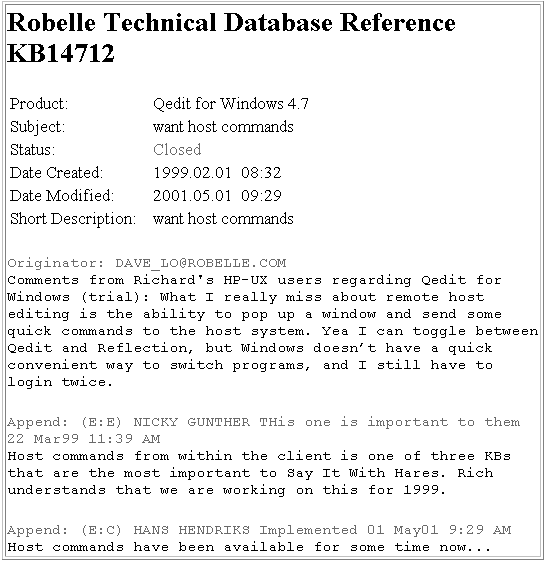
To aid customer support and provide call-tracking, Robelle technical support has been using an in-house Knowledge-Base (KB) system for over a decade, but it does not allow customer access. We thought of a browser interface to the HP e3000 database, but the issue of our customers’ privacy came up. A frequent occurrence within the call text was “Another contact is so-and-so at 555-1212.” To sanitize the thousands of historical calls in KB, would be a tremendous job, and costly. Instead, we decided to export each KB entry as an automatically sanitized Web page, allowing the customer to easily search and view the entries. A KB entry Web page would look like the example below.
Database structure
KB is stored in a TurboIMAGE database; the simplified structure of the KB database is shown below.
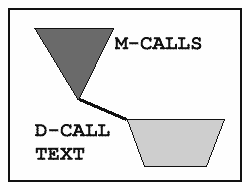
The M-CALLS set contains information unique to each entry, and is called a Master set.
The Detail Set, D-CALL-TEXT, contains doubly-linked chains of compressed text in 512-byte blocks. Although each block is a fixed length, there may be as few as two characters in the block!
Creating The Output Data...One Step At A Time
The algorithm I chose to create the Web pages is
1. Extract the data for entries to be Web-published, but not the entry text.
2. Format entry data into an HTML header.
3. Process the first record in the files.
4. Extract the text data for this entry.
5. Edit the header and combine with the text data.
6. Save results as a variable-length file (call number in the name).
7. Copy the HTML file to the Web using FTP.
8. Delete the completed entry.
9. Repeat steps 3 through 8 until the call numbers file is empty.
Algorithm implementation
Step 1: Extract the call numbers of the entries to be formatted for the Web from the KB database into a file. Robelle staff flag the entries to be Web-published. This is the easiest part.
We only select KB entries with a special “WebPost” keyword and which have been modified within the last two days. The philosophy is that technical support will mark those calls that are suitable for publication. Some calls are too boring for publication (“Please send a pre-release tape to customer X.”). And some contain private customer information from dumps and log files.
We deliberately do not extract the customer-information from the call dataset into the file, since we want the Web listings to be anonymous. This step is accomplished with Suprtool, but could probably also be done with Query.
Step 2: Format the raw IMAGE entries into HTML headers for each Web page. Each header contains unique information about the entry. We’ll format it into HTML table rows for later processing. We now have two files in the same sequence: call-numbers and formatted-headers. Recall that each header only takes up one record in the file, which allows us to keep a synchronization with the call numbers file.
This step is done by rearranging the fields and inserting literal HTML tags between fields, like producing a very odd report. We used Suprtool for this step. Here is a sample Extract command that converts the call-taker database field into an HTML line colored blue and labeled “Originator:”
ext “|lt;font color=blue|gt;Originator: “,call-taker,”|lt;/font|gt;|lt;br|gt;”
Now you might be thinking, “why go to all that trouble to insert |lt; and |gt; when I could be outputting < and > ?”
The reason is that the data extracted from the database could very well contain < and >, which would create HTML errors when viewing the page. In the sanitizing step, we will change all occurrences of < and > to < and > then change |lt; to < and |gt; to > to complete the HTML formatting.
Step 3: Process the next record of the file. We’re going to name each Web page as KB<referencenumber>.html. This will provide a simple method of maintaining files on our Web site.
While we’re at it, we’ll set the title to a variable so that we can insert it into the Web page easily in our formatting step.
Step 4: Get the Text of the Entry. Based on the call-number, we extract all of the text from the database. We will also set a variable to the call-number that we will later use to allow us to name the Web-page-file. There may be multiple text blocks for each KB entry (each containing one or more lines), so we need to do a Chained read on the call number key. The resulting text-block records are written to a file named textdata.
This step is going to be repeated over and over again until the call numbers file is empty. An interesting quirk of MPE and re-directing STDIN from a job is that you can’t use it in a loop without getting an EOF error. To get around this, we need to put our Suprtool commands inside a “use” file. Since all of the STDIN is inside a file, Suprtool re-opens it every time and the problem goes away.
Step 5: Edit the header and glue everything together. This step is truly ugly. As in Step 4, we have to stuff all of our commands into a “Use” file due to the way MPE handles EOF. We format the header and the extracted text into a single file. At this point, we have the opportunity to clean up and sanitize the text:
• We get the header.
• We change all of our internal codes into something that people will understand. For example, LQ is our internal code for Qedit, ST for Suprtool, etc.
• We change all occurrences of < and > in the textdata file to < and >.
• For our desired HTML formatting tags, we put exclamations in front of the > and < so that the HP CI doesn’t mistake them for I/O re-direction commands.
• We change our previous coding of |lt; and |gt; in header fields to be < and > for the final Web page.
• We remove unnecessary blank lines: 13 is the decimal value for Carriage Return (cr). We change two adjacent 13s into a single 13. Since our data contains cr’s as separators, and MS Windows needs crlf (carriage-return line-feed), we change all cr’s to crlf. 10 is the decimal value for line-feed.
• We add some highlighting for particular status codes of the entry.
• For each person’s comment to the entry, a date and time stamp are formatted to make it look nice.
• HP Terminal Enhancement escape sequences (which are in the data!) are modified so that they will look right.
• We remove e- mail addresses from the text to avoid our customers receiving spam email from Web-roaming spam robots.
These steps are done with a text editor, Qedit in our case.
Step 6: Save results as a variable-length file (call number in the name).
Using an MPE variable we set earlier, we name and save the file as KB<call-number>.html.
Most importantly, the file is kept as a bytestream, or variable-length file. This helps minimize the size of the Web pages. If the files were fixed length, each line of the file would require 1000 bytes. So a 40 line page would be 40K - just in text! Some KB entries are hundreds of lines long. With little effort on our part, using variable-length files makes the Web-surfer’s load-time much less.
Step 7: Copy the HTML file to the Web using FTP:
ftpit.cmd kbtogo, kb!callnbr.html, /users/WWW/kbs, daffy.robelle.com
The contents of the ftpit command file is
parm
fromfile=”?”,tofile=””,todir=””,tocpu=””
if
“!fromfile”=”?” then
echo
fromfile=”?”,tofile=””,todir=””,tocpu=””
endif
smcapset
echo user prodsend
> ftpin
echo !PRODPASS
>> ftpin
echo cd !todir
>> ftpin
echo put !fromfile
!tofile >> ftpin
echo site chmod 666
!tofile >> ftpin
ftp !tocpu <ftpin >ftpout
One important note to remember is to do a chmod 666 of the file. This allows non-owners the right to view the file. Depending upon how your FTP logon and Web server directory are set up, you may need different chmod permissions.
Steps 8 and 9: Delete the first entry from the headers file, then loop until done. We do this with an editor, by deleting the first line and saving the file again.
Much of the code written in the above steps was to set up the outer loop for execution. The loop itself is fairly simple and straightforward, done with an MPE While command and the finfo function to detect when the call numbers file is empty.
Conclusion
That’s it. The resulting KB-to-Web task runs every night on our e3000 server and generates new and replacement Web pages for our Web server. To complete the project we wrote server Perl scripts which allow you to search the KB Web pages, append comments to an existing KB entry or submit a new one (all submissions go to Robelle support who then forward them to KB). You can try the finished application at www.robelle.com/AT-kbs.html.
As you can see, the method in this project was to use scripts to combine a few dependable tools that manipulate data and text. The tools that we used were Suprtool to extract the data, Qedit to format it nicely, and FTP to transfer the files from the HP 3000 to our HP-UX Web server. This is all tied together by MPE Command Interpreter programming. No actual COBOL or C programming required. The conversion isn’t very fast, but it runs late at night and doesn’t have that great a volume to process each day. For more implementation details, read the expanded version of this article at www.robelle.com/library/papers/kbweb
— ken.robertson@robelle.com
Copyright The
3000 NewsWire. All rights reserved.