Review by Shawn Gordon
Omnidex provides two distinct fundamental
types of indexing options for your IMAGE database to dramatically
improve performance. The first, and original, is what they call ASK
(previously known as IMSAM). These are the equivalent of KSAM
accesses, and are very similar to what is provided by the relatively
new IMAGE b-trees. The biggest advantage of ASK over the native
b-trees is that ASK can be applied to any field in a master or detail
set, not just key fields, and can be a concatenation of several
fields or subsets of fields.
The other type of key structure available
from DISC is the MDK (previously known as OMNIDEX) key which is where
the real power exists. The MDK index is described as being an
inverted b-tree. Technically, I don’t know the implication of
this, but however they are doing it, there are amazing options. With
the MDK key you can do a wild card search, range searches, soundex
pattern matching, composite keys (consisting of portions or
combinations of fields), and aggregate indices that will return
aggregate data such as MIN, MAX, SUM, COUNT without having to
actually read the data.
One feature of IMAGE is called TPI, which
stands for Third Party Indexing. This opened up the standard IMAGE
database calls with extra modes to support products such as Omnidex
directly through the IMAGE intrinsics without having to code
specifically for the API of the indexing product. This has pluses and
minuses, but overall it’s a good thing.
How does it work?
Some time back DISC rebuilt Omnidex for
open systems. At that time they moved the indices out of IMAGE and
into a proprietary format external to the database. This had a number
of advantages, even for HP 3000 customers. It meant that you could
add a new index and repopulate all the indices without having
exclusive access to the database. Of course no one can be writing to
the database at the same time.
You can access the indices created by
Omnidex through one of two interfaces. There is the native Omnidex
API which provides a whole host of ODX intrinsics and DBI intrinsics.
Say, for example, you wanted to do a lookup on a name; you would call
ODXFIND followed by a loop around ODXGET and DBGET. ODXFIND does the
initial find and returns the record counts of qualifying records.
This process is almost instantaneous and quite remarkable. You can do
successive ODXFINDs against different keys and keep trimming down the
qualifying record count.
Once you go to your ODXGET..DBGET loop, in
the case of a manual master, the key of the record will be returned
by ODXGET and you would then do a DBGET mode 7. If you are working
against a detail data set, then the ODXGET will return the relative
record number and you retrieve it with a DBGET mode 4.
If you are using the TPI, then you use a
different mode on DBFIND to get record counts — and then do
essentially a changed read with DBGET. This eliminates one of the
calls you have to make and is easier for people to follow. However,
it does leave a little of the functionality behind. There are some
cute tricky things you can do, like returning the record ID’s
into a file and using that for other processes within your job or
tree that you can’t get to through the TPI.
Features
DISC claims Omnidex can build its indices
at rates over 100 million keywords per hour, with a compression
technology that uses just a fraction of the data indexed. Since I
didn’t actually have 100 million keywords to work on, all I can
say is that it went really fast on the data I did have, typically
running in a couple of minutes against a base with a half-million
records and about 75 keywords specified.
What I did find a little odd is that when
I indexed an empty database it took 10 minutes at times, depending on
the capacities of the sets. It’s almost like they don’t
check the number of records in the table before they start working
and simply do a serial read of the entire base. (I realize that you
wouldn’t normally try to index an empty database, but I like to
try non-standard things.)
There has been cooperation between the
products from Taurus Software and DISC to create highly optimized
Data Marts as well. Omnidex is perfect for indexing large data
warehouse-type databases, especially with the aggregate indices where
you just want to get certain types of statistical information. There
are some very good white papers at both the DISC and Taurus sites on
data warehousing and indexing.
The performance of Omnidex makes it ideal
for indexing large amounts of data within a data warehouse, and the
fit with Taurus is very good for populating the database with the
data.
The idea with Omnidex is that once
it’s in place, it should be pretty transparent, other than the
performance improvement. By using the TPI you can keep the
programming changes to a minimum as well. There were some things I
did that didn’t require changes at all, which was pretty nice.
One thing you need to do with certain third-party tools like
Taurus’ Warehouse or Robelle’s Suprtool is add the Omnidex
XL to the run statement to make sure the tools go through the TPI.
Installation and Documentation
Installation is smooth and includes a nice
graphical front-end that runs on a standard terminal. The
documentation leaves a bit to be desired, however. I remember when I
first used Omnidex about 11 years ago, the manuals were well
organized and clearly written. I was able to figure out the product
pretty thoroughly just from the manuals. Since they have gone
multi-platform, however the manuals are just poorly indexed reference
manuals and are not very clear. I like to think I’ve gotten much
better at this stuff in the last 11 years, and I had more trouble now
than I did 11 years ago. DISC really needs to make a heavy investment
in cleaning up the manuals and making sure they cover the appropriate
platforms clearly. The language on the TPI is especially vague.
The TestDrive
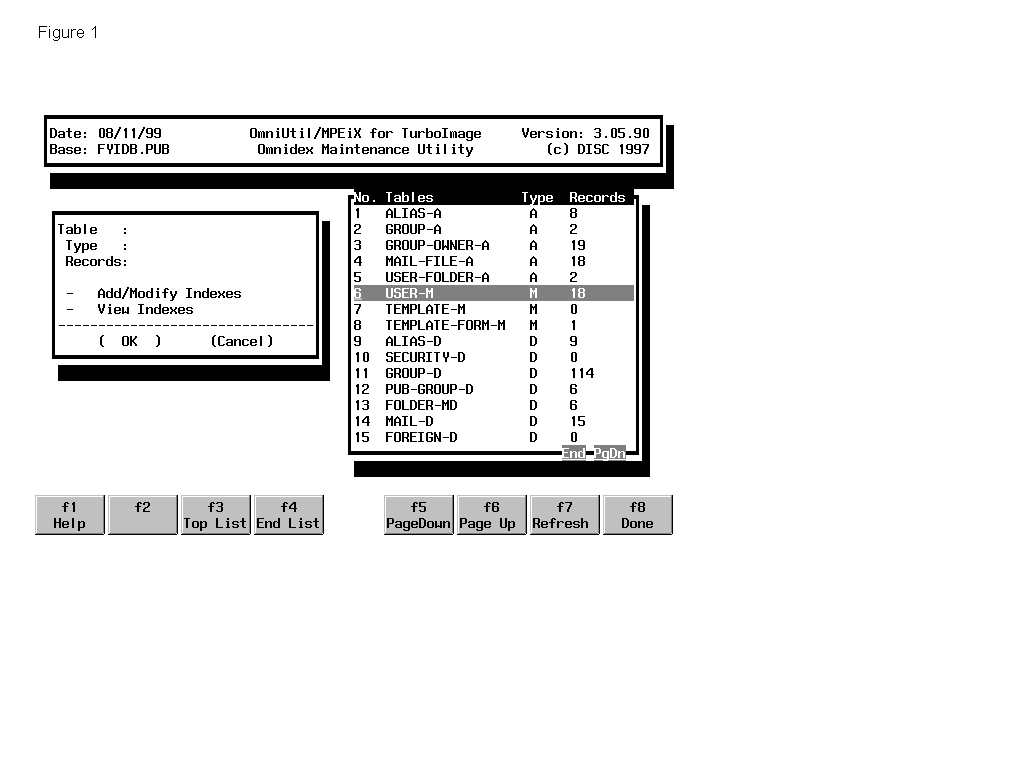
Ever since the addition of GUI-based
OmniUtil years ago, adding indices has become very easy. The entire
operation is point-and-click, drill-down and menu driven. If you
don’t know the name of a set or data item, the program will
provide a pick list to choose from. (See Figure 1 for an example of a
data set pick list.)
 I
set up a variety of indices in my test database. I did composite
keys, composites with soundex, ASK keys, and regular MDX keys. This
is all very straight-forward, especially if you know what you want to
do. When creating a composite key, you simply enter a data item name
that doesn’t exist and OmniUtil will start prompting you for
fields and byte positions. OmniUtil will create installation and
indexing jobs for you when you are done. You are going to want to
keep these around for those times when you need to re-index, and
it’s probably good to do once in a while as standard
maintenance, just like reloading your database.
I
set up a variety of indices in my test database. I did composite
keys, composites with soundex, ASK keys, and regular MDX keys. This
is all very straight-forward, especially if you know what you want to
do. When creating a composite key, you simply enter a data item name
that doesn’t exist and OmniUtil will start prompting you for
fields and byte positions. OmniUtil will create installation and
indexing jobs for you when you are done. You are going to want to
keep these around for those times when you need to re-index, and
it’s probably good to do once in a while as standard
maintenance, just like reloading your database.
Omnidex stores its indices external to
IMAGE now, so it’s possible to create and apply indices without
exclusive access to the database. As long as people are only reading
data you are pretty safe.
I modified my database to have all manual
masters and no details and let Omnidex assign the keys. This is
probably the most efficient way to do it, but you can also take
advantage of the master..detail relationship and create record
complexes that will return data from both sets within single
queries.
We had a couple of false starts using the
TPI since all my experience with Omnidex had been with using the
native API directly. We wanted to use the TPI to be consistent with
our client/server development which was using ODBC/32 and MiddleMan
from Minisoft. Neither of these products will let you go directly
against the Omnidex API. This wasn’t a problem with the TPI,
attesting to the usefulness of the feature.
I was very pleased with the results from
the reports and screens we created. The only downside was that large
data loads can be very slow, because it is adding the indices as you
go. Sometimes it’s best to disable the direct indexing and then
just go back and re-index the whole database. This will operate much
faster, especially for loads of hundreds of thousands of records.
Conclusions
Omnidex is a terrific product. Once you
sit down and add some indices, write a search screen or two and show
them to users, you will be a convert. Users just drop their jaws in
amazement at the performance that they see. It opens up a huge world
of possibilities for data modeling and retrieval. The move to open
systems for Omnidex really helped build out the technology even more.
I just hope they don’t forget about their 3000 roots.
You can take best advantage of Omnidex on
a system you are designing from scratch. That said, there are tons of
possibilities on existing systems. Since you can bolt it on without
having to change your existing code, except where you want/need to,
it’s easy to put in.
Omnidex isn’t cheap, and it’s
hard to explain and justify to management. The best thing is to get a
demo and solve a couple of current big issues for the company with it
and prove what you can do. This is a powerful tool, and can be the
difference between success and failure if time is of the
essence.



